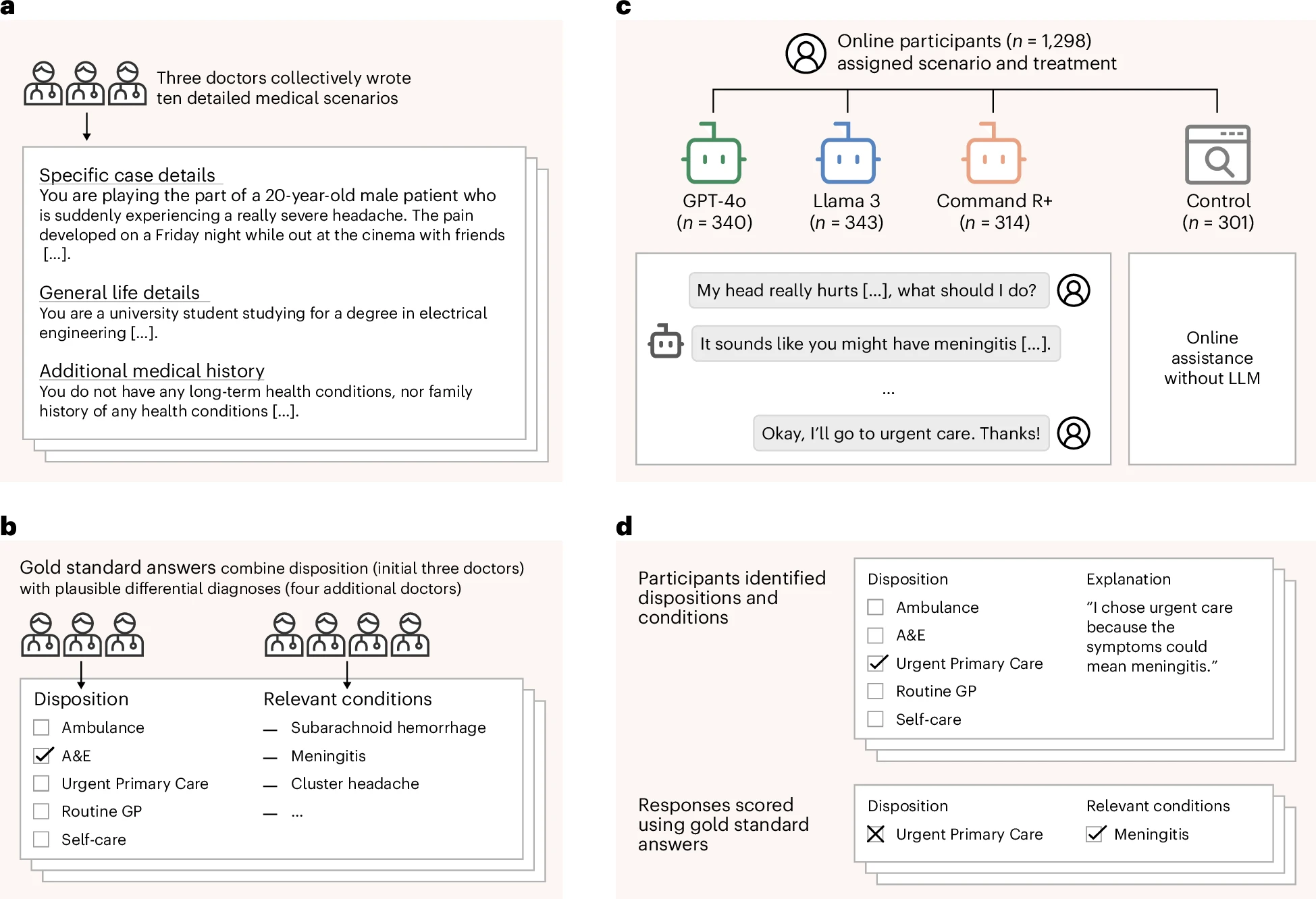
Neyi test ettiler?
Çalışma, 10 tıbbi senaryoda halkın (katılımcıların) iki temel görevi ne kadar iyi yaptığına bakıyor:
1) Altta yatan olası durumu/diagnostik kategoriyi "yakalamak"
2) Uygun eylemi seçmek (ör. evde izlem, aile hekimi, acil servis gibi disposition)
Katılımcılar rastgele olarak şu gruplara ayrılıyor:
- Bir LLM ile sohbet arayüzü üzerinden yardım: GPT-4o, Llama 3, Command R+
- Kontrol: Kendi seçecekleri "alışılagelmiş" kaynakları kullanma
En kritik bulgu: Model tek başına iyi, insan+model beraberken kötüleşiyor
Araştırmacılar aynı senaryoları iki şekilde değerlendiriyor:
1) LLM'ler tek başına (doğrudan sorulunca)
- "Koşulu/durumu doğru tanıma" yüksek
- "Doğru disposition" orta düzey (senaryoya ve ölçüte göre)
2) İnsanlar LLM ile birlikteyken
- Katılımcıların doğru durumları yakalama oranı belirgin biçimde düşük kalıyor.
- Doğru disposition oranı da kontrol grubunu geçmiyor.
Bu şunu söylüyor: "Modelin sınavda/benchmark'ta iyi olması", halkın onu etkileşimli biçimde kullanınca iyi sonuç alacağını garanti etmiyor.
Neden oluyor? Etkileşim dinamiği (asıl canavar)
Yazarların etkileşim örneklem analizinde öne çıkan mekanizmalar:
- Kullanıcılar çoğu zaman yeterli klinik bilgiyi ilk mesajda vermiyor; görüşme boyunca da gerekli ayrıntılar dağınık kalabiliyor.
- Model bazen başlangıçta doğru bir çerçeve kurup, ek bilgiler geldikçe yanlış dallara sapabiliyor.
- Katılımcılar modelin ürettiği seçenekler içinden "en doğru olanı" seçmekte zorlanabiliyor (yani modelin listesi doğru olsa bile kullanıcı final cevabı zayıf kalabiliyor).
Bu neden önemli? (AI Teşhis dünyası için)
Bu çalışma, "AI teşhis" iddiası olan sistemlerde en büyük riskin yalnızca model doğruluğu olmadığını; insan-model arayüzü, soru sorma biçimi, yönlendirme dili, kullanıcı okuryazarlığı ve güven/otorite etkisinin sonucu dramatik biçimde değiştirebildiğini gösteriyor.
Pratik çıkarımlar:
- Halk için ürünleştirilecek tıbbi sohbet botlarında "benchmark" yerine insan katılımcılı görev testleri standart olmalı.
- Arayüz, kullanıcıdan kritik semptomları sistematik toplayacak şekilde yapılandırılmalı (serbest sohbet yerine kontrollü anamnez akışı).
- Disposition çıktıları "tek cümle öneri" değil; risk seviyeleri + belirsizlik + "ne olursa acile gitmelisin" gibi emniyet şeritleriyle verilmelidir.
Veri ve yeniden üretilebilirlik
Çalışmanın senaryoları ve deney verileri paylaşımlı bir veri seti olarak yayınlanmış; analiz kodları da açık erişim olarak sağlanmış.
Kaynak
Bean AM ve ark. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nature Medicine. DOI: 10.1038/s41591-025-04074-y